Esse artigo nasceu enquanto eu estudava otimizações de consulta no Spark. Resolvi documentar o processo e compartilhar o que fui aprendendo.
O que acontece por baixo dos panos quando você filtra dados
Quando você escreve um filtro no Spark, o sistema precisa decidir um coisa: vai buscar todos os dados e filtrar depois, ou vai filtrar antes mesmo de ler? Essa decisão tem impacto direto no volume de dados lidos, no tempo de resposta e no custo da consulta. O mecanismo responsável por fazer essa escolha de forma inteligente é o Predicate Pushdown.
O que é o Predicate Pushdown
O predicate é a condição que você quer aplicar, como um WHERE pais = 'Brasil'. O pushdown é empurrar essa condição para baixo na pilha, até o nível de quem lê o arquivo, antes de qualquer dado ser movido. Juntos, formam um dos principais mecanismos de otimização do Spark.
Não é exclusividade do Spark
Essa otimização existe em várias tecnologias. SQL Server, BigQuery e DuckDB são alguns exemplos, cada uma com sua implementação. O que muda é o componente responsável. No Spark, esse papel é do Catalyst, um otimizador embutido que analisa o plano de execução e identifica quais filtros podem ser antecipados. Quando você roda uma query com filtro em cima de uma tabela Delta, o Catalyst repassa o predicado direto para o leitor do Parquet, que usa as estatísticas internas dos arquivos para pular blocos inteiros que não atendem à condição, sem nem abri-los.
Por que isso importa na nuvem
No fim, menos dados lidos significa menos tempo de resposta e menos custo, o que faz bastante diferença em ambientes de nuvem onde você paga pelo que processa.
Nas próximas seções vamos ver como o Catalyst aplica essa otimização e como confirmar que ela está acontecendo nas suas consultas no Microsoft Fabric.
Como o Predicate Pushdown funciona por dentro
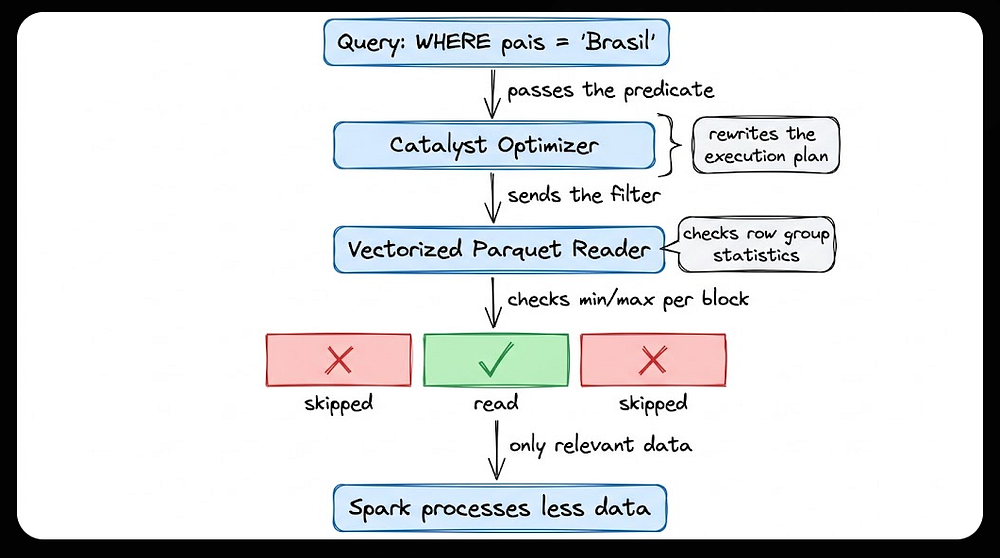
Entender o Predicate Pushdown no Spark exige conhecer dois atores: o Catalyst e o Vectorized Parquet Reader. Os dois trabalham juntos, cada um com seu papel.
O Catalyst: reorganizando o plano antes de executar
Quando você escreve uma query, o Catalyst não a executa diretamente. Ele primeiro a reescreve em um plano de operações mais eficiente.
Pensa assim: toda query vira uma árvore onde cada nó é uma operação, leitura, filtro, join. O Catalyst olha para essa árvore e a reorganiza, mantendo o mesmo resultado mas com um custo menor.
Em uma query com JOIN e filtro, por exemplo:
SELECT v.valor, c.nomeFROM vendas vJOIN clientes c ON v.cliente_id = c.idWHERE v.pais = 'Brasil'
O plano ingênuo seria: lê tudo, faz o join, aplica o filtro. O Catalyst percebe que o filtro pais = 'Brasil' pode ser aplicado antes do join e o move para mais perto da leitura. O Spark entra no join já com uma tabela muito menor.
O Vectorized Parquet Reader: pulando o que não precisa ser lido
Mas o Catalyst vai além de reorganizar operações. Ele passa o predicado para o Vectorized Parquet Reader, o componente que lê os arquivos fisicamente.
O leitor não abre cada arquivo e varre linha por linha. Ele consulta o cabeçalho de cada arquivo, onde ficam as estatísticas dos row groups, blocos internos que guardam o valor mínimo e máximo de cada coluna. Se as estatísticas indicam que aquele bloco não pode conter pais = 'Brasil', ele pula o arquivo inteiro sem abrir nenhuma linha.
É como procurar uma palavra num livro usando o índice em vez de ler página por página.
O resultado
No fim, o Spark recebe só os dados que passaram pelo filtro, sem ter lido tudo. O Catalyst foi esperto na ordem das operações. O leitor do Parquet foi esperto na leitura dos arquivos. Os dois juntos são o que chamamos de Predicate Pushdown na prática.
Vendo o Predicate Pushdown na prática
Para tornar o conceito mais concreto, vamos ver o Predicate Pushdown acontecendo de verdade. O exemplo usa uma tabela Delta chamada vendas_demo, com 5 milhões de registros de pedidos, criada e armazenada no OneLake dentro do Microsoft Fabric. O código roda em um Spark Notebook conectado ao lakehouse lh_teste.
O filtro é simples: queremos apenas os pedidos do Rio Grande do Sul.

O explain() imprime o plano físico que o Spark vai executar. Independente da tabela que você usar, é nesse output que você vai procurar a evidência do pushdown.

O filtro estado = 'RS' foi repassado pelo Catalyst diretamente para o Vectorized Parquet Reader. Antes de qualquer linha chegar à memória do Spark, o leitor já consultou as estatísticas dos row groups e pulou os blocos que com certeza não contêm registros do RS.
Se o pushdown não tivesse acontecido, o campo PushedFilters apareceria vazio, e o filtro só seria aplicado depois que todos os dados já estivessem na memória.
Na sua tabela Delta, o processo é o mesmo. Basta rodar o explain() em qualquer query com filtro e procurar pelo campo PushedFilters no output.
Conclusão
O Predicate Pushdown é uma daquelas otimizações que trabalha silenciosamente em segundo plano. Você escreve um filtro simples e o Spark já evita ler o que não precisa, sem nenhuma configuração da sua parte.
Vimos o conceito, entendemos o papel do Catalyst e do Vectorized Parquet Reader, e confirmamos com o explain() que o pushdown estava acontecendo de verdade numa tabela Delta no Microsoft Fabric.
Nos próximos artigos vamos explorar como essa otimização se comporta em outras fontes de dados e quando ela pode não funcionar como esperado.

Deixe um comentário